Foundational Models for Time-series Analysis
Introduction
Time-series analysis is a statistical technique used to analyze data points collected or recorded at specific time intervals. Unlike traditional data analysis, time-series methods focus on capturing temporal patterns, trends, seasonality, and cyclic behaviors in data. These insights help predict future values, enabling informed decision-making. Time-series analysis is widely employed in numerous industries due to its ability to leverage historical data for forecasting and strategic planning. Time-series analysis is widely used across industries for its predictive power. In finance, it supports stock price prediction and risk management. Retailers and e-commerce platforms leverage it for demand forecasting and inventory optimization, while healthcare uses it for monitoring patient trends and predicting outbreaks. Additionally, energy providers rely on it for consumption forecasting, and logistics companies use it to optimize routes and delivery schedules.
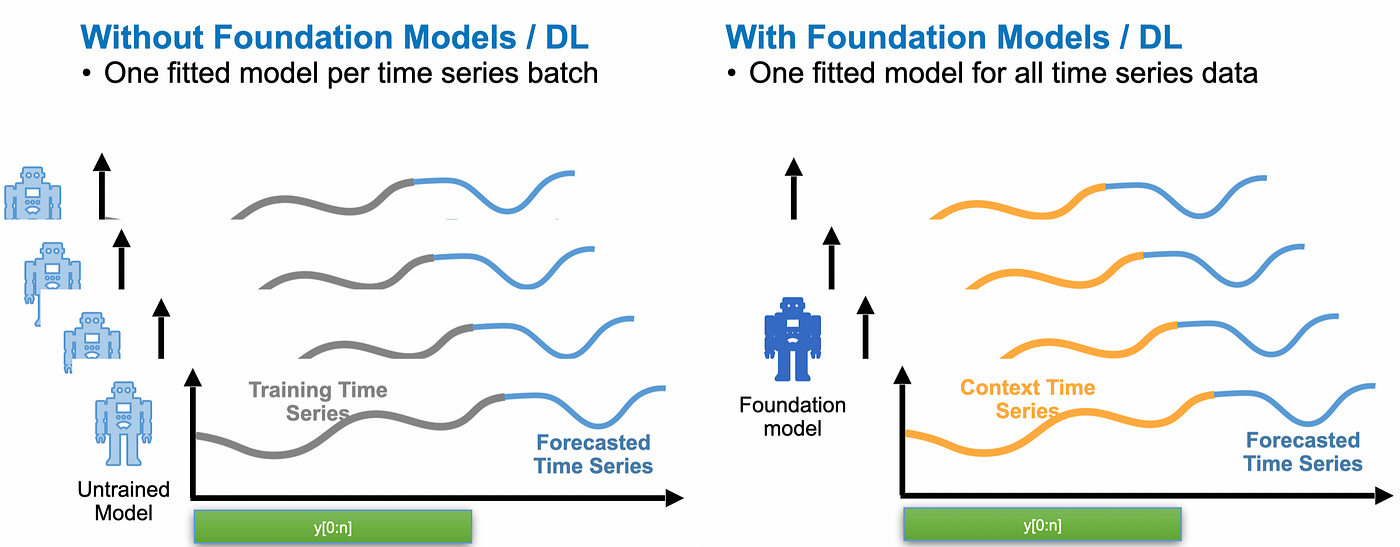
Foundational models perform more effectively and efficiently in comparison to standard statistical models.
Key Challenges in Real-World Deployment
Simple Models are not enough
One of the key challenges in time-series analysis is the demand for highly accurate forecasts and predictions, especially in critical applications such as financial market analysis, healthcare monitoring, and energy demand planning. These time-series have complex patterns and temporal dependencies that simple off the shelf models cannot capture reliably. Building custom models for each of the applications require careful feature engineering, model design and extensive validation to ensure reliability under diverse conditions. All of these require significant human and compute resources and are not generalizable across applications.
Lack of Sufficient Data Availability
Another significant challenge is the lack of sufficient or high-quality data. Many state-of-art time-series models rely on large datasets to identify patterns and make accurate predictions, but historical data may be incomplete, sparse, or unavailable for newer or smaller-scale use cases. Moreover, external factors like changes in data collection methods or system updates can introduce inconsistencies, making it difficult to create reliable models. Data scarcity is particularly problematic in cases where the target variable is rare or event-driven, such as equipment failures or disease outbreaks.
Adapting to Different Tasks and Target Variables
Time-series analysis often needs to adapt to different tasks, such as predicting various target variables that may have unique characteristics and temporal patterns. For instance, forecasting stock prices involves different considerations compared to predicting electricity usage or classifying time-series data in healthcare. Moreover, in many real-world scenarios, time-series data must support multiple tasks, such as simultaneous forecasting, classification, and anomaly detection. Each task may require tailored preprocessing, feature extraction, and modeling approaches, making it challenging to create generalizable solutions that perform well across diverse applications and tasks.
Samay: A Multi-task Multi-domain Time-series Model
Foundational models pre-trained on diverse domain datasets offer high potential in overcoming these key challenges. These models leverage large-scale pretraining across a variety of datasets and tasks, enabling them to learn generalized representations of temporal patterns and adapt to specific applications with minimal fine-tuning or even without any training.
Addressing Data Scarcity
Foundational models can mitigate the challenge of limited data availability by transferring knowledge from related domains. For example, a model pre-trained on diverse time-series datasets—such as financial, weather, and retail data—can effectively learn transferable patterns that apply to new tasks with limited data with little to no fine-tuning.
Accurate Forecasts and predictions
Pretrained foundational models can improve forecasting accuracy by leveraging patterns learned across multiple domains and datasets. These models capture both universal and domain-specific temporal trends, allowing them to generalize better to new data or scenarios.
Deploying for Multiple Tasks Simultaneously
Our Foundational model is well-suited for multi-task learning due to its architecture and other technical novelties. Their ability to capture rich representations across diverse datasets makes them capable of supporting multiple objectives—such as forecasting and classification—within a unified framework. This holistic approach streamlines workflows and enhances the utility of time-series models in complex, real-world applications.
Comparison with other Foundational Models
We compare the performance of LPTM with other state of the art foundational models that are openly available using the industry standard MAE (mean Abslute Error) score. On comparing against across wide range of benchmarks in the fields of demand forecasting, finance, sales, electricity and epidemiology, our solution is consistently better than the rest by a significant margin.
| Benchmark/Models | TimesFM | Chronos | MOIRAI | Lag-LLAMA | LPTM |
|---|---|---|---|---|---|
| ETT1 | 0.58 | 0.59 | 0.62 | 0.64 | 0.49 |
| ETT2 | 0.49 | 0.52 | 0.55 | 0.57 | 0.46 |
| Flu-US | 1.32 | 1.21 | 1.31 | 1.46 | 0.79 |
| Flu-Japan | 1214 | 1228 | 1336 | 1416 | 704 |
| PEM-Bays | 3.7 | 3.7 | 3.9 | 3.9 | 2.5 |
| NY-Bike Demand | 2.8 | 3.1 | 3.5 | 2.9 | 2.4 |
| NY-Taxi Demand | 12.19 | 12.82 | 13.71 | 13.43 | 11.84 |
| Nassdaq | 0.22 | 0.27 | 0.24 | 0.28 | 0.17 |
| M4 | 1.07 | 1.04 | 1.21 | 1.33 | 0.94 |
Scalability with Model Size
LPTM is also much smaller at around 150 million parameters compared to other solutions that range from 500 million to 2 billion parameters. This allows LPTM to deployed at a wider range of low resource computing platforms and can be deployed at a in settings with requirements of lowers latency and high throughput applications such as finance and sales forecasting.